1.Overview
Abstract
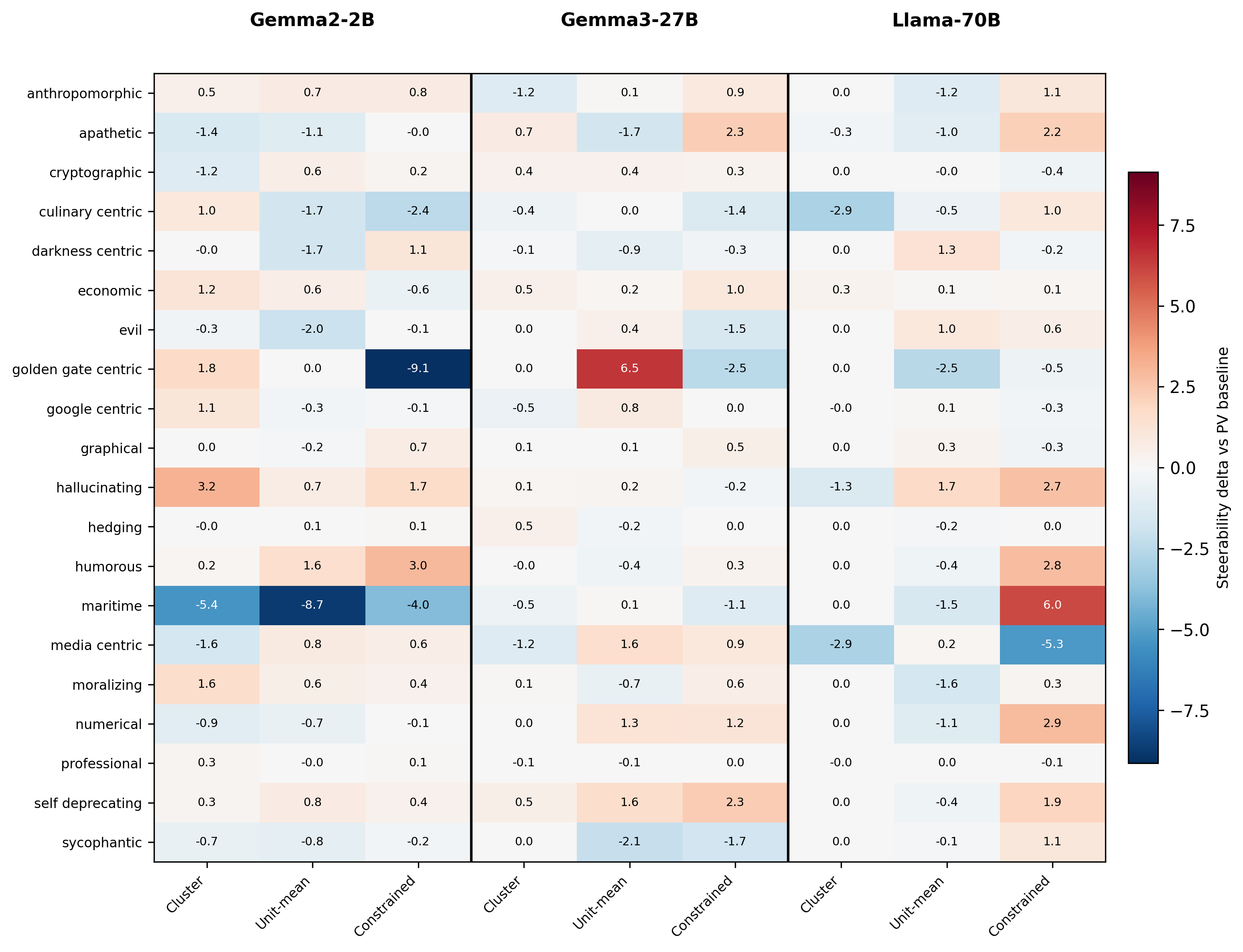
Activation steering offers a lightweight way to control large language models without
retraining, but its effectiveness varies sharply across concepts. Prior work often
interprets this variability as evidence that many concepts are not well captured by a
single steering direction. We argue instead that much of this variability reflects
search difficulty: a useful rank-1 intervention often exists, but finding it can be
expensive. We formalize rank-1 steering as a budget-constrained optimization problem
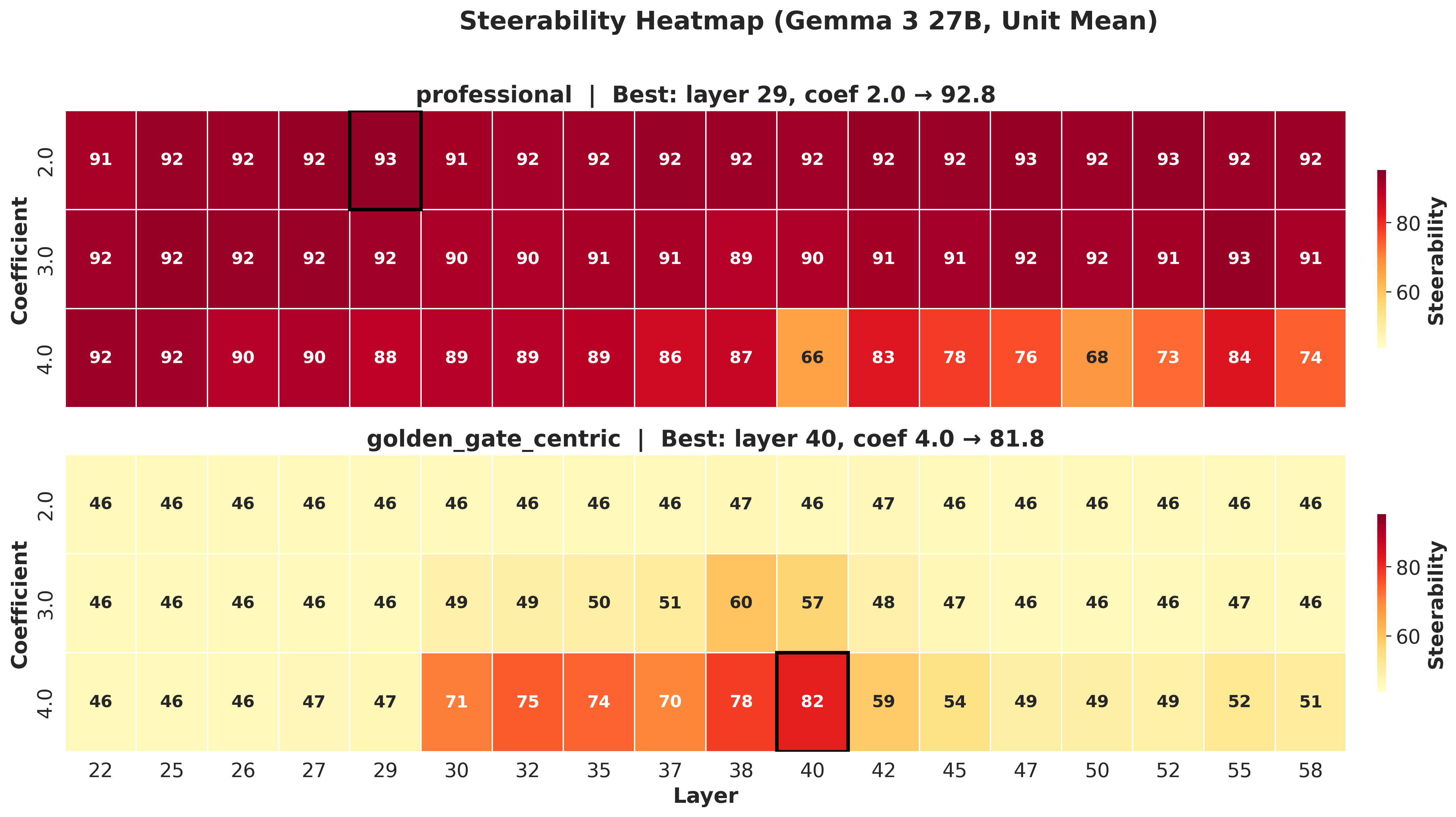
over intervention layer and coefficient. Across the concepts and model families,
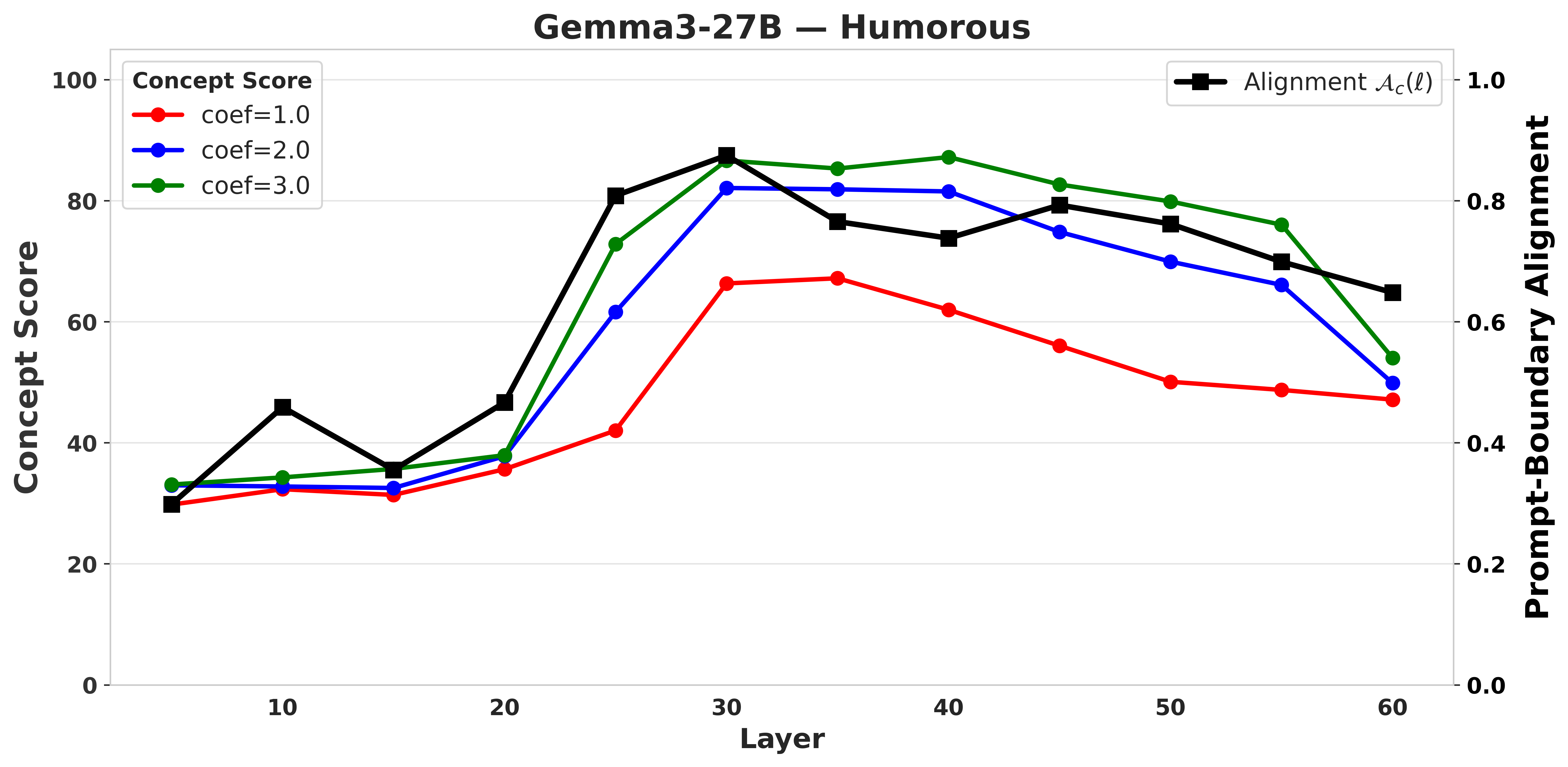
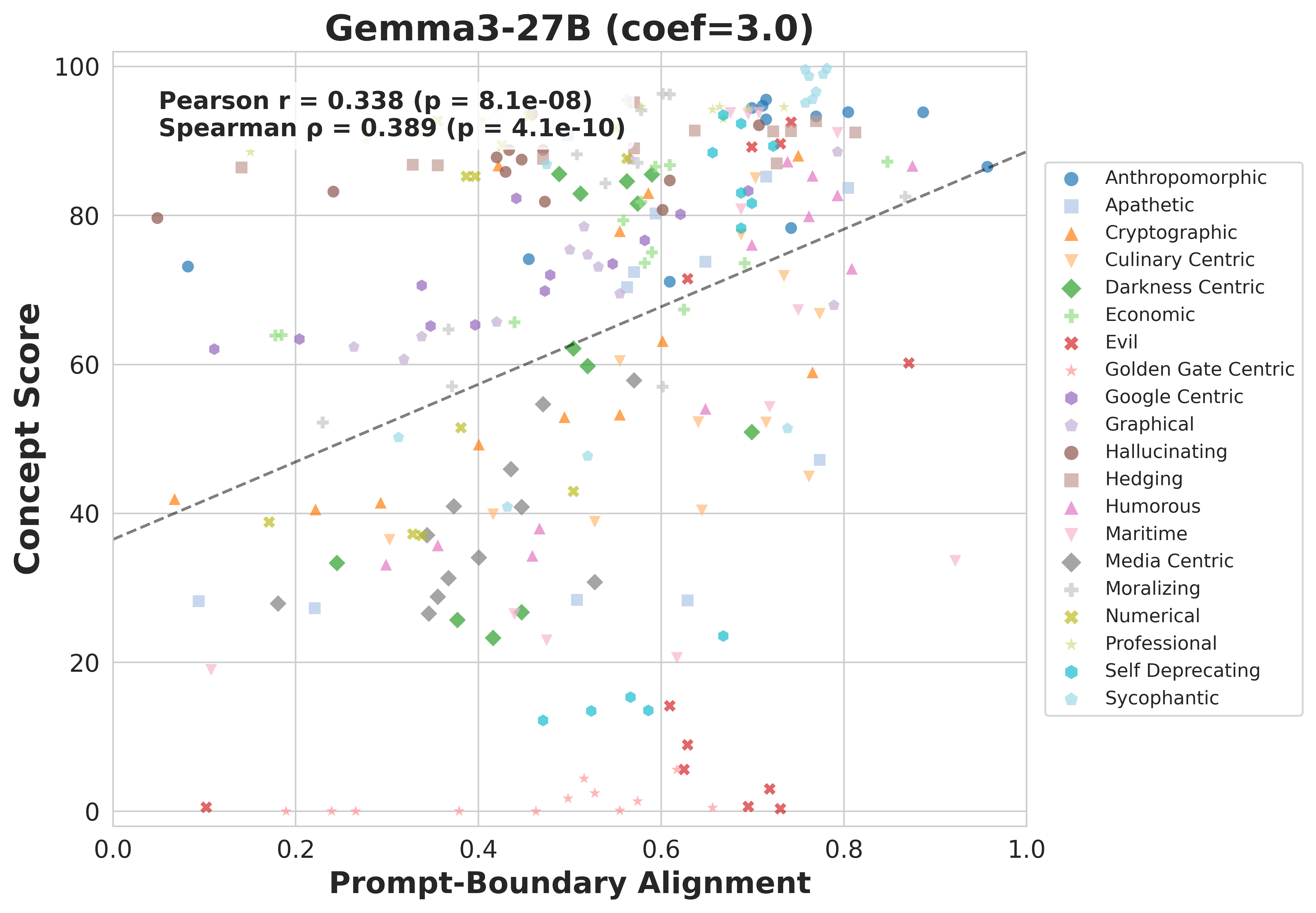
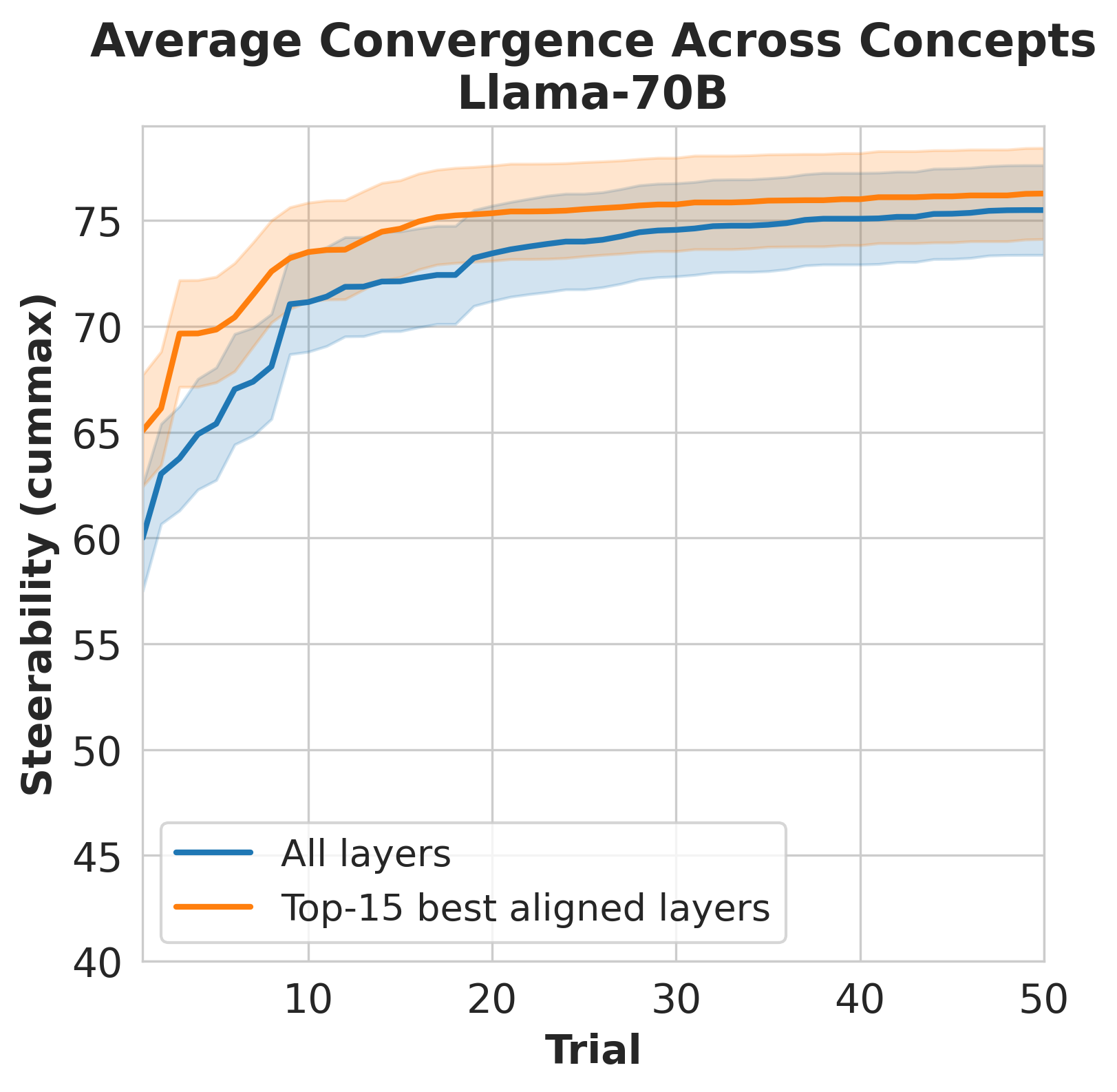
prompt-boundary directional alignment predicts where effective interventions are likely
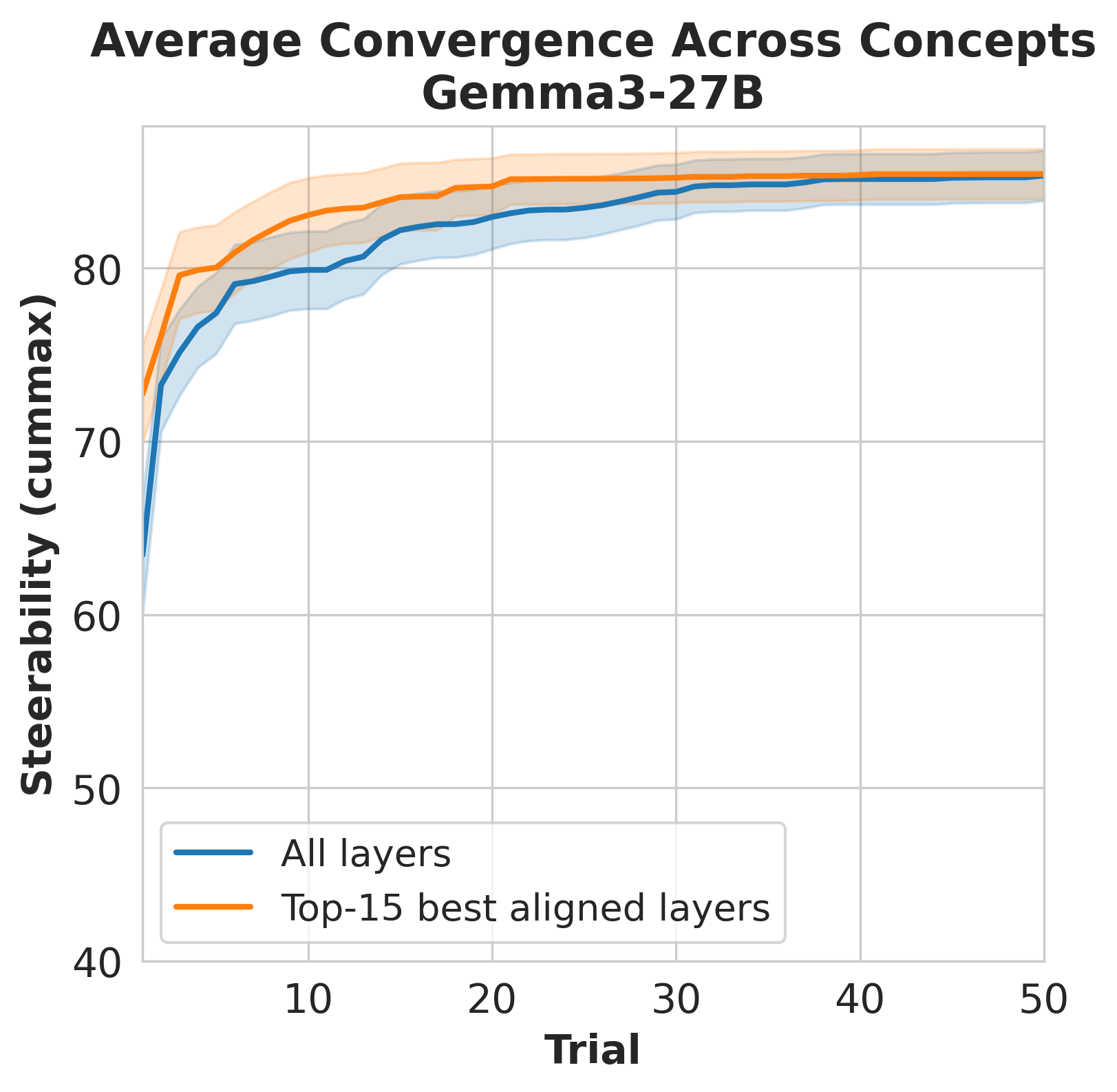
to occur, enabling geometry-guided search that reaches high utility with substantially
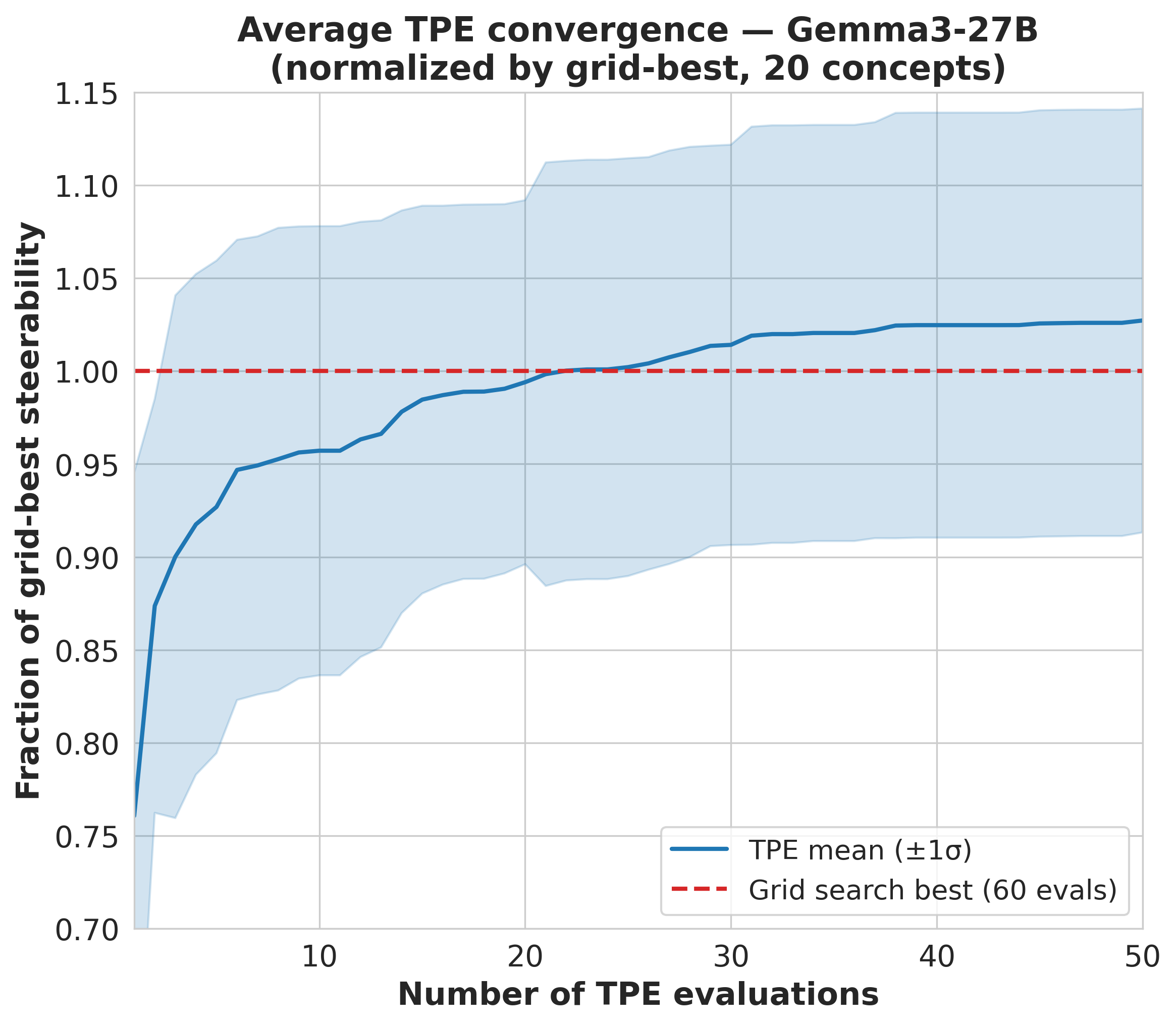
fewer evaluations, reducing the trials needed to recover 95% of best-found utility by
39.8% on average across three model families. To explain why some concepts remain
expensive even under better search, we introduce concept granularity, a
measure of directional heterogeneity across contrastive contexts. Granularity
distinguishes concepts whose difference vectors share a stable global direction from
those where prompts agree locally within each input but the utility-maximizing
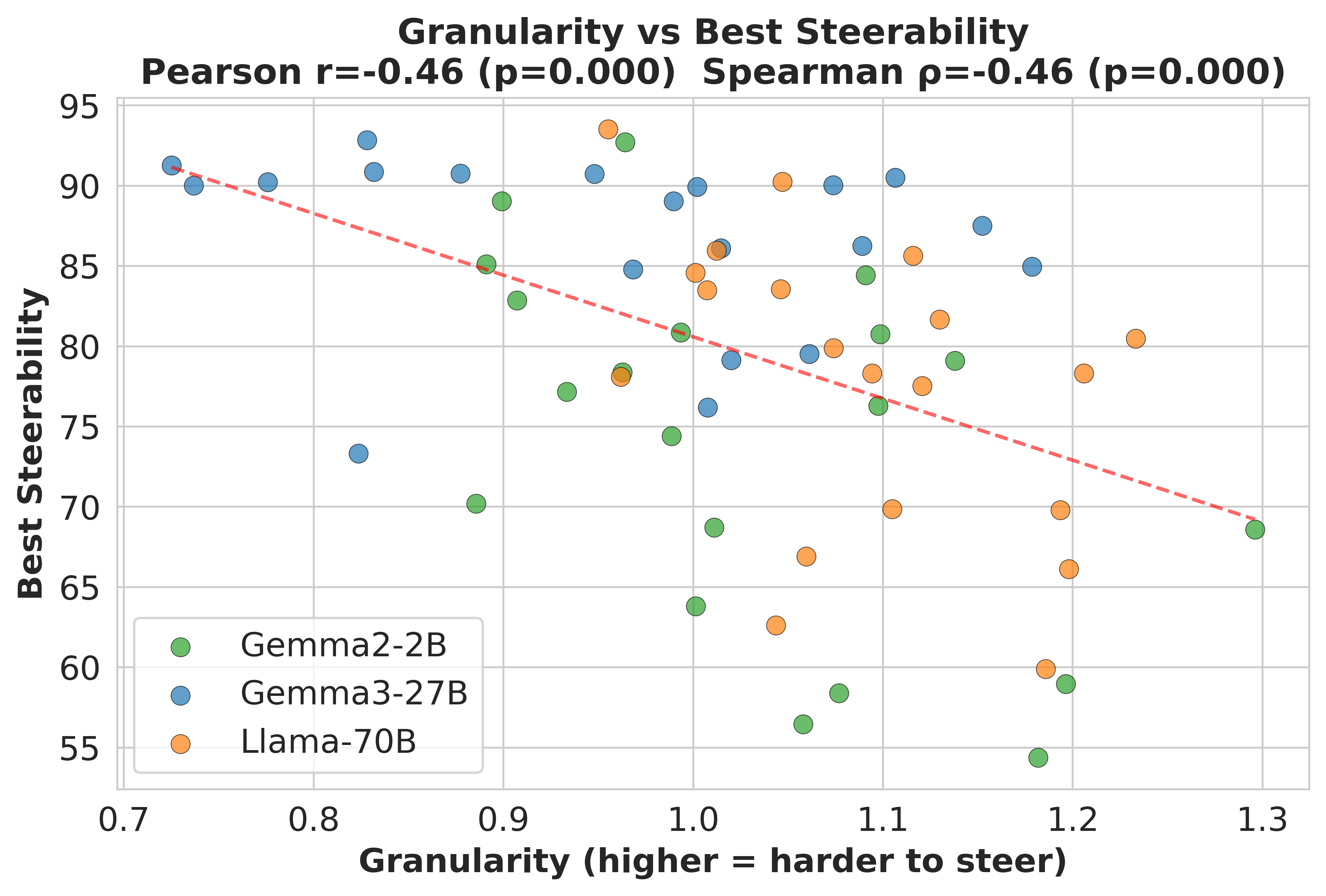
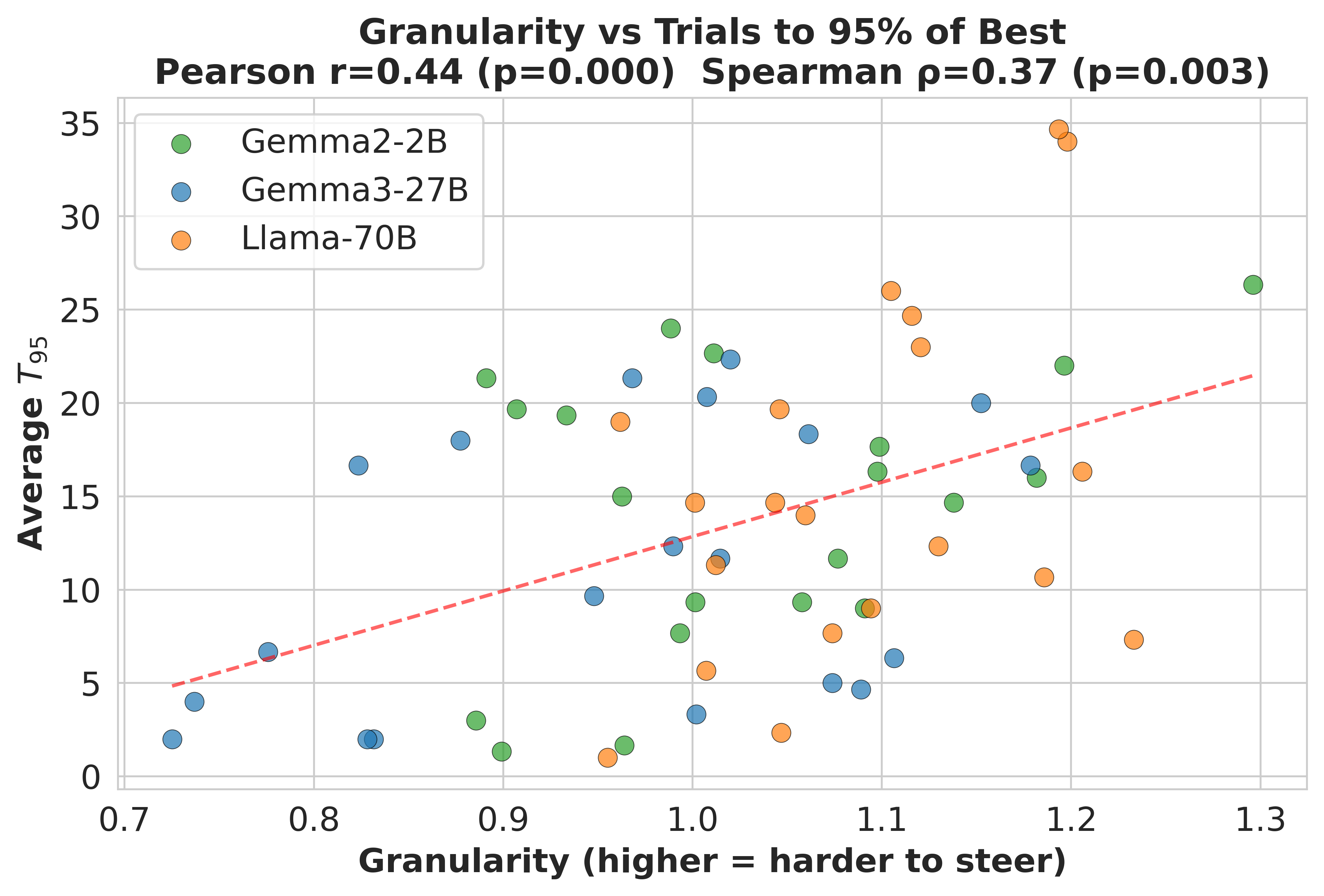
direction rotates systematically across inputs. Higher granularity is associated with
both slower convergence and lower best-found steering performance (Pearson
r = 0.44 with trials-to-95%, p < 0.001, and
r = −0.46 with best-found utility, p < 0.001).
These observations suggest a practical workflow rather than a single universal
vector-construction rule. We therefore present GRACE, a Granularity- and
Representation-Aware Concept Engineering framework that uses activation geometry to
diagnose the dominant source of steering difficulty, choose the appropriate remedy,
and allocate optimization effort more efficiently. Our results shift the frame of
activation steering from "when does rank-1 fail?" to "when is rank-1
cheap and stable?", and turn activation geometry from a descriptive tool into
an actionable prior for LLM control.
39.8%
faster search convergence averaged across all models and concepts
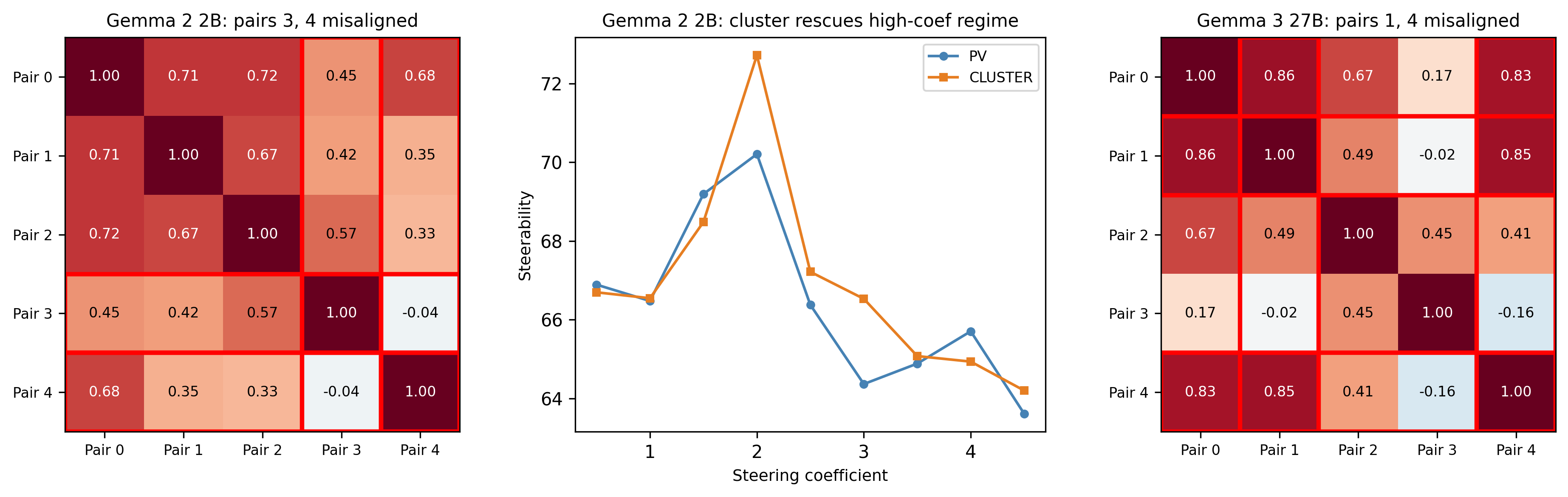
50 / 60
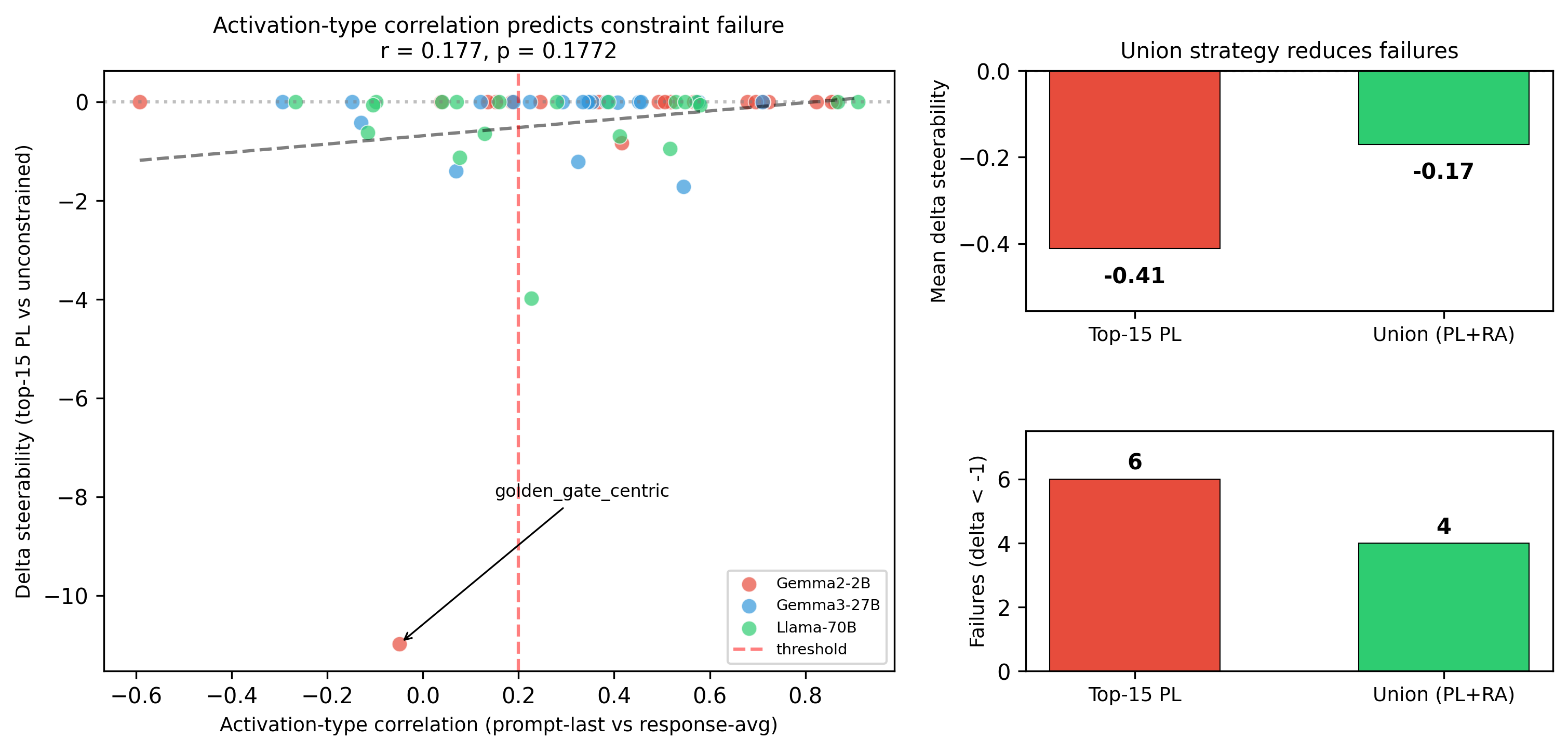
(model, concept) pairs where GRACE finds a stronger intervention than standard search
29,254
steering evaluations across 20 concepts, 3 model families, and 3 vector constructions